1.希尔(Shell)插入排序基本思想
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因DL.Shell于1959年提出而得名。
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为dl的倍数的记录放在同一个组中。先在各组内进行直接插人排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt−l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
该方法实质上是一种分组插入方法。实际上当dt=1时,完全就是直接插入排序。但是经过多个分组的直接插入排序,最后一次完整的插入排序前数据表几乎已经是排好序了,因此shell sort充分利用了直接插入排序在数据表几乎已经有序的条件下工作高效的特点。
希尔算法的具体过程如下:
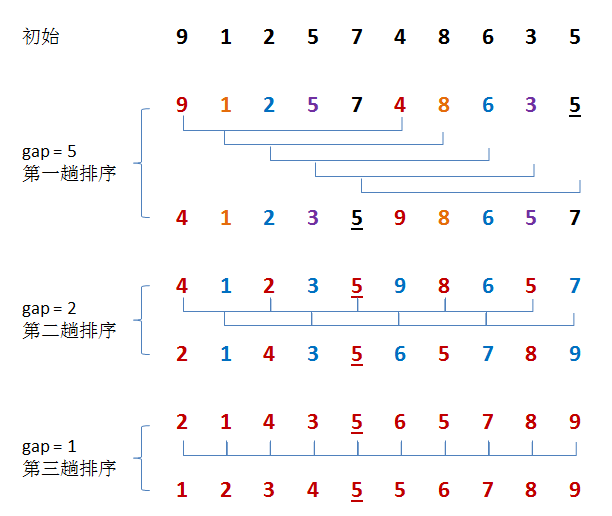
希尔排序示意图
2.希尔(Shell)插入排序算法分析
(1)增量序列的选择
Shell排序的执行时间依赖于增量序列。
(2)好的增量序列的共同特征
a.最后一个增量必须为1;
b.应该尽量避免序列中的值(尤其是相邻的值)互为倍数的情况。
c.经验总结:当n较大时,比较和移动的次数约在nl.25到1.6nl.25之间。
(3)希尔Shell排序的时间复杂度
希尔排序的时间性能优于直接插入排序的原因:
a.当数据表初态基本有序时直接插入排序所需的比较和移动次数均较少;
b.当n值较小时,n和n2的差别也较小,即直接插入排序的最好时间复杂度O(n)和最坏时间复杂度0(n2)差别不大;
c.在希尔排序开始时增量较大,分组较多,每组的记录数目少,故各组内直接插入较快,后来增量di逐渐缩小,分组数逐渐减少,而各组的记录数目逐渐增多,但由于已经按di−1作为距离排过序,使数据表较接近于有序状态,所以新的一趟排序过程也较快。
因此,希尔排序在效率上较直接插人排序有较大的改进。
(4)希尔(Shell)插入排序稳定性
希尔排序是不稳定的。两个相同关键字在排序前后的相对次序是可能发生变化的。
这个方法对于大的数据集效率其实并不高,但是它是一个对小数量数据表(小于1000)进行排序的最快算法之一。另外,相对使用的内存较少。
3.直接插入排序和希尔排序的比较
(1)直接插入排序是稳定的;而希尔排序是不稳定的。
(2)直接插入排序更适合于原始记录基本有序的集合。
(3)希尔排序的比较次数和移动次数都要比直接插入排序少,当N越大时,效果越明显。
(4)在希尔排序中,增量序列gap的取法必须满足:最后一个步长必须是 1 。
(5)直接插入排序也适用于链式存储结构;希尔排序不适用于链式结构。
4.希尔排序C语言源代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | /** * 算法君:一个专业的算法学习分享网站 * 算法君:专业分享--数据剖析--算法精解 * 算法君:http://www.suanfajun.com */ #include<stdio.h> #include <stdio.h> void shellsort(int *a, int n) { int i, j, k, t; k = n / 2; while(k > 0) { for(i = k; i < n; i++){ t = a[i]; j = i - k; while(j >= 0 && t < a[j]) { a[j + k] = a[j]; j = j - k; } a[j + k] = t; } k /= 2; } } int main() { int a[] = {8,10,3,5,7,4,6,1,9,2}; int N; N = sizeof(a) / sizeof(a[0]); shellsort(a, N); for(int k = 0; k < N; k++) printf("a[%d] = %d\n",k,a[k]); return 0; } |
5.希尔排序C++源代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | /** * 算法君:一个专业的算法学习分享网站 * 算法君:专业分享--数据剖析--算法精解 * 算法君:http://www.suanfajun.com */ #include <iostream> #include <iomanip> using namespace std; // 打印输出函数 void print(int ar[], int sz, int step) { for(int i = 0; i < sz; ++i) { if(((i + 1) % step) != 0) cout << setw(3) << ar[i]; else cout << setw(3) << ar[i] << endl; } cout << endl; } //希尔排序算法函数 void ShellSort(int a[], int sz) { int i, j; int step, temp; step = sz / 2 ; while(step) { print(a, sz, step); cout << "==>" << endl; for (i = step; i < sz; i++) { temp = a[i]; j = i; while (j >= step && a[j - step] > temp) { a[j] = a[j - step]; j = j - step; } a[j] = temp; } print(a, sz, step); cout << "current array" << endl; print(a, sz, sz); cout << "----------------" << endl; step = step / 2.2; } } int main(void) { int a[] = {13, 14, 94, 33, 82, 25, 59, 94, 65, 23, 45, 27, 73, 25, 39, 10}; const size_t sz = sizeof(a)/sizeof(a[0]); cout << "Initial array" << endl; print(a,sz,sz); cout << "-------------" << endl; ShellSort(a,sz); cout << "Sorted array" << endl; print(a,sz,sz); return 0; } |
